Director's Corner
24 September 2009
 Ewan Paterson |
Operating and maintaining the ILC in the year 202X
Today's issue features a Director's Corner by Ewan Paterson, Member of the Global Design Effort Executive Committee.
Why is it that a group of us within the Global Design Effort are discussing some possible year-long operating and maintenance schedules for the ILC while it is still under design and some years away from operation? It is because the schedule for frequency and duration of time to repair, maintain and upgrade equipment can affect system design and R&D on component development and we need to think about these things now in order to be ready when the ILC comes online.
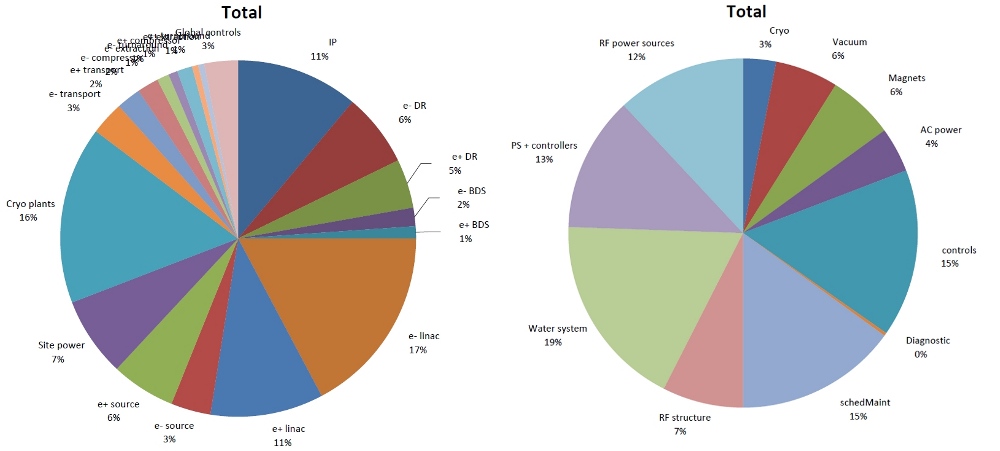 Interim results for strawman baseline 2009 parameters and this operating schedule. Interim results for strawman baseline 2009 parameters and this operating schedule. |
The currency in which we measure success in high-energy physics with colliders is the delivered integrated luminosity. This is the product of the average luminosity – the rate of particle collisions in a given area per second – and the time that it is available, based on scheduled running time minus unscheduled downtime. Estimating the latter is a very complex problem which includes estimates of component or system failure rates, (mean time between failures or MTBF), the mean time to repair, MTTR, and the impact on other accelerator systems when an upstream system prevents beam from continuing into the downstream systems. This latter condition is when these systems lose their most important and inclusive diagnostic and tuning tool: the beam itself. The more complex the accelerator design the more complex is this estimating exercise.
This is an old problem in accelerator design and various tools have been used to aid the designers. For the ILC a more comprehensive approach has been to develop an actual computer model of accelerator operation which tries to include the years of experience with working accelerators, both good and bad. For example it models not only the time required to correct a problem in one system, but the possible impact on other systems and the time it takes to recover the operating performance of all systems. Some issues become even more important with very large facilities where the people and spare parts might be kilometers from where they are needed and the distance between access points is also measured in kilometres. There is no such thing as a five-minute fix, a minimum of one or two hours may be more likely, and this increases the impact of small problems which is often ignored. As is normal with computer models, they must be used carefully with a clear understanding of the built-in assumptions, and the old adage, garbage in gives garbage out, still applies.
Before and during the development of the Reference Design Report (RDR) the computer program Availsim (see Barry's Director's Corner from 3 September) was used to estimate the 'availability', the time integrating luminosity, assuming that the ILC component failure rates would be similar to other accelerators around the world. This showed, as expected, that due to both the much larger number of individual components and complexity of operation it would be difficult to achieve the goal of 85 percent uptime which is typical of large high-energy accelerators. To achieve this, with some contingency, would require for many systems either improvements in component reliability, increased redundancy or some combination of both. The worst culprits were identified and design changes made providing redundancy in operation of some components. In addition, R&D goals were set for engineering developments, leading to longer operating lifetimes where providing redundancy would be impractical or too expensive.
An example from the RDR is "Power supplies and electronics: Power supplies are designed to have modular architecture with an extra module for redundancy. Most electronics modules not in the accelerator tunnel are designed to be replaceable without interrupting power to their crate. This allows broken modules to be replaced without further impact on the beam." As an example, high-availability power supplies were developed at SLAC and prototypes are installed and operating at ATF2 at KEK. The assumption here was that most equipment such as these or similar modules or klystrons and modulators were accessible for replacement while the ILC was operating. This was just one of the arguments for the twin-tunnel design where a support tunnel, or equivalent alcoves, paralleled the beam tunnel, and were accessible to personnel while the accelerator was in operation. In the ongoing studies of a single-tunnel design, this assumption about access would no longer be valid and the scheduled opportunities for this and other types of equipment maintenance become an important consideration in determining the overall accelerator system availability.
 This is what an operating schedule for the ILC could look like. This is what an operating schedule for the ILC could look like. |
What are the general requirements for scheduling maintenance, repair and upgrades? In general, system-wide upgrades and or work on cold superconducting systems will require extended shutdowns. When one has to bring one section (2.5 kilometres) of the superconducting linac up to room temperature for repair or upgrade, it is estimated that we need one week for warm-up and one for cooldown. Therefore, no less than one month should be scheduled for this activity whereas many other activities, including machine development, benefit from relatively frequent downtimes of a duration of a few shifts. It is assumed that time scheduled for the "push-pull" of detectors could be used for some combination of machine maintenance or development. In the RDR the schedule was assumed to be nine months of operation and three of scheduled downtime. Here it would be redistributed as two one-month downs separated by six months and a series of short interruptions which integrate to a month and would be distributed as required by operational needs. This (example) operating schedule for 2022 as shown, is being used in Availsim for evaluating machine availability in the strawman baseline 2009 studies. The two alternate linac radiofrequency systems, klystron cluster and distributed radiofrequency (RF), (read also Barry's corner from 23 July) have both been shown to be effective in maintaining adequate linac availability in comparison to the original RDR solution for any reasonable overall operating conditions and schedules.
Studies of this kind for all ILC systems are ongoing and results will be reported at ALCPG 09 workshop in Albuquerque, US. Some of the interim results for strawman baseline 2009 parameters and this operating schedule are shown in the pie charts. As one can see, everyone contributes to lost time and will argue that the simulation is unfair to their system or component design. I propose a test of the simulation. As anyone who has many years of experience with the operation of large accelerators will agree: Major failures and downtimes begin on Friday evenings after everyone has gone home for the beginning of a three-day holiday weekend. Does Availsim predict this or tell me to check the real statistics and NOT my memory? I will take the answer offline!
-- Ewan Paterson